제1정규형  |
| first normal form, 1NF, 第一正規形 [데이터통신] |
| 관계 데이터베이스에서 관계의 모든 속성값이 더 이상 분해할 수 없는 원자적(atomic)이고 기본적인 값으로 구성되어 있는 관계. 제1정규형은 가장 단순한 구조로 된 레코드의 집합(예:직원 명단)으로 각 필드(열)는 식별 번호나 성명 같은 하나밖에 없는 중복되지 않은 정보만을 포함한다. 제1정규형을 분해하여 필드 간의 상호 관계를 점점 더 세부적으로 규정함으로써 몇 개의 다른 표들로 분리시킨 것이 제2정규형과 제3정규형이다. |
| 제2정규형 |
| second normal form, 2NF, 第二正規形 [데이터통신] |
| 관계 데이터베이스에서 관계의 형식은 제1정규형인데 키가 아닌 모든 속성이 그 관계의 어떤 후보 키(candidate key)에도 전함수 속성(fully-functional dependency)일 경우의 관계. 키가 아닌 속성이란 관계의 속성이 어떠한 후보 키로도 되어 있지 않은 것을 말한다. |
| 제3정규형 |
| third normal form, 3NF, 第三正規形 [데이터통신] |
| 관계 데이터베이스에서 관계의 형식은 제2정규형인데 키가 아닌 어떤 속성도 그 관계의 1차 키(primary key)에 추이 종속(transitive dependency)되지 않는 경우의 관계. |
| 제4정규형 |
| fourth normal form, 4NF, 第四正規形 [데이터통신] |
| 관계 데이터베이스에서 관계 R가 보이스코드 정규형(BCNF)인데 자명한 다치 종속 관계 A//B가 성립되지 않고, R 내의 모든 속성 X가 A에 함수 종속 관계(A/X)인 경우에 R를 가리키는 용어. 다치 종속 개념을 사용하지 않고 어떤 관계가 보이스코드 정규형인데 몇 개의 키가 단일 속성으로 구성되어 있는 경우를 제4정규형이라고 정의해야 한다는 주장도 있다. |
| 제5정규형 |
| fifth normal form, 5NF, 第五正規形 [데이터통신] |
| 관계 데이터베이스에서 제4정규형을 일반화한 것으로 R. Fagan이 도입한 정규형. 관계 R가 제4정규형이고 관계 중에서 성립되는 모든 결합 종속성(join dependency)이 그 관계의 후보 키만으로 논리적으로 함축되어 있는 경우에 그 관계를 제5정규형이라고 한다. 다치 종속성의 개념을 사용하지 않고 다음과 같이 정의하는 논자도 있다. 어떤 관계가 제3정규형의 관계이고 모든 키가 단일 속성으로 구성되어 있는 경우에 그것을 투영/결합 정규형(PJ/NF:project/join normal form) 또는 제5정규형이라고 한다. |
정규화(Normalization)
정규화는 논리적 데이터 모델을 일관성이 있고 중복을 제거하여 보다 안정성을 갖는 바람직한 자 료구조로 만들기 위해 여러 단계를 거친다. 그 단계는 제 1차 정규형에서부터 제 5차 정규형과 BCNF(Boyce-Codd Normal Form)까지로 구성되어 있다. 대체로 적절하고 일관성을 유지하면서 중복이 없는 논리적 데이터 모델을 구축하는 데에는 흔히 3차 정규형이 사용된다.
정규화의 의미
잘 만들어진 데이터 모델이라고 해도 엔터티에 데이터를 삽입, 수정, 삭제할 때 오류가 발생할 개연성을 가지고 있다. 이러한 것들을 통칭해서 변경 이상(Modification Anomaly)이라고 한다. 여기에는 구체적으로 삽입 이상(Insertion Anomaly), 수정 이상(Update Anomaly), 삭제 이상 (Deletion Anomaly) 등이 있다.
변경 이상이 발생하는 엔터티를 그대로 운용하게 되면 데이터가 신뢰할 수 없는 값들로 채워질 가 능성이 있다. 즉, 데이터의 일관성, 무결성을 해칠 가능성이 있는 것이다.
정규화 과정을 통해서 변경 이상의 엔터티를 정규화된 엔터티로 변환하게 된다.
1) 입력 이상
별도의 사실이 발생하기 전까지 원하는 데이터를 삽입할 수 없음. 어떤 데이터를 삽입하려고 할 때 불필요하게 원하지 않는 데이터도 함께 삽입되게 된다.
2) 삭제 이상
일부 정보를 삭제함으로써 유지되어야 할 정보까지도 삭제되는 연대 삭제가 발생한다. 제3장 논리 데이터 모델링
3)갱신 이상
일부 속성 값을 갱신 함으로써 원하지 않는 정보의 이상 현상(무결성 파괴, 정보의 모순성)이 발생 한다.
정규화의 장점
1) 중복값이 줄어든다
궁극적으로 칼럼 간, 레코드 간, 테이블 간에 중복되는 데이터들을 최소화할 수 있다. 이것이 정규 화의 최대 성과라고 할 수 있다. 사실은 모든 장점이 이것에서 시작된다.
2) NULL 값이 줄어든다
전체적으로 NULL 값의 사용이 줄어들게 된다.
3) 복잡한 코드로 데이터 모델을 보완할 필요가 없다
데이터에 중복된 값이 적고, 그 부모가 누구인지가 항상 명시되어 있는 상황에서 데이터의 무결성을 지키기 위한 복잡한 코드를 사용할 필요가 없어진다. 데이터베이스 코드를 작성하는데 복잡한 변환 과정과 조인 질의, NULL 값 처리들이 필요하다는 것은 그 데이터베이스 설계가 문제가 있다는 말이 기도 하다.
4) 새로운 요구 사항의 발견 과정을 돕는다
실제 정규화 과정에서 많은 엔터티 혹은 속성들이 태어나게 된다. 또한 많은 결정 과정에서 업무 담 당자와의 협의를 통해서 현재뿐만 아니라 미래까지도 고려한 요구 사항의 발견 과정이기도 하다.
5) 업무 규칙의 정밀한 포착을 보증한다
정규화 과정을 통하여 많은 복잡한 업무 규칙들이 체계화되고, 규칙의 Value화에도 도움을 주게 된다.
6) 데이터 구조의 안정성을 최대화한다
중복된 값이 최소화되고 모든 정보들이 자기가 있어야 할 자리에 존재하게 되기 때문에 향후 발생 하게 될 모델 변화에도 유연하게 대처할 수 있다.
정규화 단계
1) 1차 정규형 (1NF, First Normal Form)
가) 정의
· 모든 속성은 반드시 하나의 값을 가져야 한다. 즉, 반복 형태가 있?일한 이름을 가져야 한다.
· 레코드들은 서로 간에 식별 가능해야 한다.
나) 정규화 작업
[그림 1] 에서와 같이 고객 엔터티의 계약일 속성의 값이 여러 건이 된다면 1차 정규형을 위배하는 것이 된다.
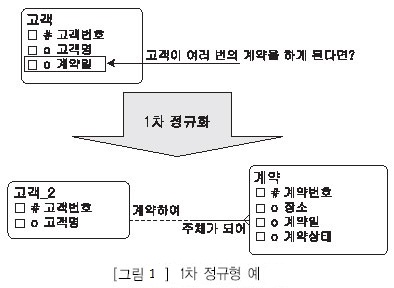
· 어떤 속성이 다수의 값을 가지고 있다면 M:1 관계의 새로 엔터티를 추가한다.
· 관계형 모델에서는 관계(Relation) 정의상 한 속성이 하나의 값만을 가져야 한다. 그러므로 비정규형 관계는 엄밀히 말하면 관계로 간주할 수 없다.
· 비정규형 관계가 관계로서의 모습을 갖추기 위해선 여러 개의 복합적인 의미를 가지고 있는 속 성이 분해되어 하나의 의미만을 표현하는 속성들로 분해되어야 한다. 즉 속성수가 늘어나야 한 다.
· 비정규형 관계가 관계로서의 모습을 갖추기 위해선 하나의 속성이 하나의 값을 가질수 있어야 하며,이 조건을 만족시키기 위해선 튜플이 늘어나야 한다. 또는 다른 관계로 분리되어야 한다.
· 분석 또는 모델링 진행 과정에서 발생하며, 최종적인 모델링 완성 단계에서는 나올 수 없다. 그 러나 분석(모델링) 초기 단계에는 상세히 분해된 속성보다는 위와 같은 레벨의 속성 추출이 복잡 도를 줄일 수 있으므로 실전에서는 효율적이고 유리하게 이용될 수도 있다.
2) 2차 정규형 (2NF, Second Normal Form)
가) 정의
· 식별자가 아닌 모든 속성들은 식별자 전체 속성에 완전 종속되어야 한다.
· 이것을 물리 데이터 모델의 테이블로 말하면 기본키가 아닌 모든 칼럼들이 기본키에 종속적이어 야2차 정규형을 만족할 수 있다는 것이다.
나) 정규화 작업
· [그림 2]에서와 같이 식별자가 학번 + 코스코드로 이루어진 학과등록 엔터티에서 학번속 성에 평가코드, 평가내역 속성들이 종속적이다. 그렇기 때문에 이것은 2차 정규형을 위반하고 있는 것이다.
· [그림 2]에서와 같이 식별자가 학번 + 코스코드로 이루어진 학과등록 엔터티에서 코스코 드 속성에 코스명, 기간 속성들이 종속적이다. 그렇기 때문에 이 또한 2차 정규형을 위반하고 있 는 것이다.
· 의미상의 주어 즉, 본질식별자를 알아야 식별자 부분 종속인지를 구분할 수 있다. 제3장 논리 데이터 모델링
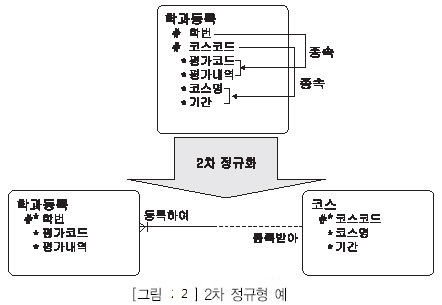
· 속성의 의미가 명확해야 종속성을 비교할 수 있다.
· 어떤 속성 식별자 전체에 종속되어 있지 않으면 잘못된 위치이며 새로운 엔터티 즉, 상위 부모 엔터티를 생성하고 UID BAR를 상속받게 된다.
3) 3차 정규형(3NF, Third Normal Form)
가) 정의
2차 정규형을 만족하고 식별자를 제외한 나머지 속성들 간의 종속이 존재하면 안된다. 이것이 3차 정규형을 만족하는 것이다.
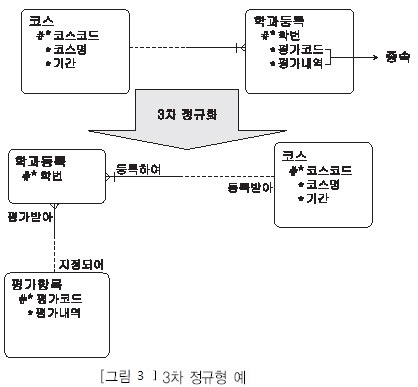
나) 정규화 작업
· [그림 3]에서 학과등록 엔터티에서 평가코드, 평가내역 속성들이 서로 간에 종속적이다. 즉, 평가내역 속성은 평가코드 속성에 종속적이다. 그렇기 때문에 이것은 3차 정규형을 위반하 고 있는 것이다.
· 3차 정규형을 위반하고 있을 시에는 [그림 5-3-11]에서의 평가항목 엔터티처럼 부모 엔터티가 생성되고 그 부모 엔터티로부터 UID Bar가 없는 관계를 상속받게 된다.
4) BCNF 정규형
가) 정의
· 모든 결정자가 키인 릴레이션이 BCNF이다. 반대로 어떠한 결정자 하나라도 키가 아닌 릴레이 션이라면 BCNF가 될 수 없다.
· 기존의 2차 정규형과 3차 정규형을 보완하려는 목적으로 만들어졌다. 즉 부분 종속이나 이행 종 속이 없는 3차 정규형도 변경 이상 현상이 나타날 수 있기 때문이고, 이것은 어떤 Non-Key 속 성이 결정자로 동작하기 때문에 발생한다.
나) 3차 정규형의 문제점
· 한 릴레이션에 여러 개의 후보키(Candidate Key)가 있으며,
· 모든 후보키들이 적어도 둘 이상의 속성으로 이루어지는 복합(Composite) 키이며,
· 모든 후보키들이 적어도 하나 이상의 공통 속성이 포함되는 경우이다.
다) 3차 정규형을 만족하고 BCNF가 아닌 경우
· 각 속성이 단 하나의 값으로 구성된 경우(1차 정규형)
· Non-Key 속성인 D는 후보키(Candidate Key)인 A+B 또는 B + C 에 완전 함수 종속이므로 2차 정규형에 속한다.
· 또한 Non-Key 속성이 D 하나 뿐이므로 Non-Key 속성 간의 종속 관계가 존재하지 않으므로 제 3차 정규형을 만족한다.
2차 정규화는 모든 일반 컬럼은 반드시 여러개의 PK 로 구성된 컬럼중 특정 하나의 PK 컬럼에만 종속되어서는 안되고 전부에 종속적이어야 한다는 것
3차 정규화는 PK 가 아닌 일반 컬럼에 종속적인 컬럼이 있는지 조사하는 것
'Dev. > Back-end' 카테고리의 다른 글
| SmartEditor2 사진첨부기능 이미지업로더 (JSP model1) (3) | 2013.06.27 |
|---|---|
| JSP로 RSS구현하기 예제 (0) | 2013.06.10 |
| Ubuntu 10.10 에 Sql Developer 설치하기 (0) | 2012.10.16 |
| Oracle 연습문제 2~7장 (1) | 2012.10.14 |
| Ubuntu 12.04(x86) 에 Oracle11g Tomcat7 JDK1.7 Eclipse 깔기. (0) | 2012.10.04 |

댓글